SAP123
Level up your SAP reports with SQL
Willem Hoek on Oct 23, 2017
This is a follow up from Why SAP Business Analysts should know and use SQL
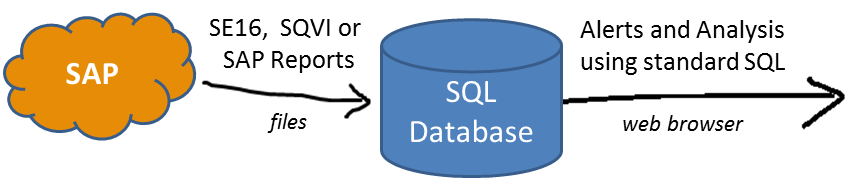
In this post we will focus on a simple example to get SAP data in an external database and then produce a basic SQL report. If you have access to SAP and specifically if you can run SE16N or any other report you should be able to follow along and create a SQL report based on your own data coming from SAP.
Who is this post aimed at?
SAP Business Analysts who are familiar with SE16 and Excel and want to speed up the analysis process by start using SQL.
What do I need?
Access to a SAP system, then download a program called Spoolkit I wrote for you to follow along in the post.
Do I need to know SQL?
It would be great if you do - else use this as an incentive to learn the basics. If you can master a simple select statement you are halfway there!
Table of contents
- Background
- What is Spoolkit?
- Spoolkit Installation
- SQLite database
- End to End example
- Getting data from SAP
- Download file to your PC
- Load data in database with Spoolkit
- View the data in SQLite
- Build SQL report in Spoolkit
- Run SQL Report
- Downloads and Support
- Support
- Downloads
[u]Background [/u]
Typical process used : you run SE16N or other SAP reports, download the results to your PC. Import it into Excel and after lots of cleaning up, filtering, vlookup, pivot table and other magic you get the end results. This is perfect for exploratory once off work but time consuming and error prone if you need to do same thing on a regular basis, example as a routine process to check quality of master data. A SQL database is ideal for repetitive analysis. It takes longer to set up but lot quicker to replicate the analysis.
I have written a software tool called “Spoolkit” to get SAP spool files quickly in a database on your PC. This version of Spoolkit requires no installation. Simply download the EXE file, save it on your PC and run it. You can download the prototype software from xxxxxx
What is Spoolkit [/u]
SpoolKit is a software program to: Quickly load SAP files in a standard SQL database running on your PC or local network. You create the data files by running SE16, SQVI or other SAP reports in the background and downloading them to your PC. Once data is in the database you can create Spoolkit reports with standard SQL or use existing reporting tools.
It has been used successfully in the following business scenarios:
- Daily check of master data quality
- Create data conversion files and automate post migration checks
- Automate merging of multiple SAP reports into one new report
- Manage exceptions in business transactions where existing report does not yet exists
This does not replace SAP reports or any BI tools - it simply automate process of working with SAP ECC reports. Emphasis is on quick analysis and prototyping. The requirements when building Spoolkit was:
- Rapid prototyping: Must be able to get a report going in minutes rather that days or weeks.
- Work with SAP Standard: Use data and transactions available to the average SAP power user. In this case the results of SE16 or other SAP reports are used. There are some fantastic commercial reporting and BI tools available but they all require specialize extractors or other ABAP programs to be loaded. With this solution, if you can download print spool files (SM37, SP01) you are OK. This also limits the capability - but remember this is not a replacement of your existing reports, simply a way to enhance and automate reports from SAP.
- Data never leaves your PC: For security and privacy reasons data must stay on local PC. So solution had to be an application running locally and not a cloud or SaaS type solution.
- No 3rd party software required: For the OSS (Open Source Software) version of Spoolkit there is no need to install or have access to a database. Hence the decision to use SQLite database engine. Spoolkit can also be used with client server type databases such as PostgreSQL, MySQL and others. Contact me if you need more info.
- Simple to install: In this case, just download and execute the EXE. It can even be run from a memory stick
- Easy to un-install: Just delete directory and database file and everything is gone.
[u]Spoolkit Installation [/u]
Save downloaded file in a separate folder somewhere on your PC. The same folder will be used to store the SQLite database file. In example below I saved the downloaded file in C:\spoolkit\
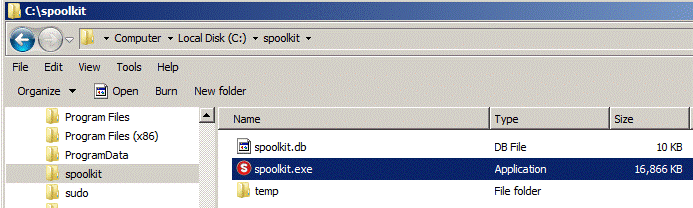
Just double click on spoolkit.exe start. When running the program it will open up a command line window that runs a small web-server â leave that open in the background.

![]()
With the program running in the command line window – the URL to access the program is http://localhost:9119/ No username or password is required as it is a single user program. Program will also open up your default browser with this URL.
SQLite database for OSS version
SQLite is the OSS (Open Source) version of Spoolkit, so no install is required for basic SQL queries. The SQLite database file (spoolkit.db) will be created in the same folder as where the spoolkit.exe file was saved. For more complex queries - a client server database will be more suitable, recommended solution is PostgreSQL.
End to End example
Key steps that we will be following are:
SAP
- Run a report in SAP (in BACKGROUND mode) so that it generate a SAP spoolfile (SP01)
- Download SAP file it to your PC
Spoolkit
- Define the format of SAP file (once off per file type)
- Load the data file in the database
- Build a SQL report
- Run the SQL report
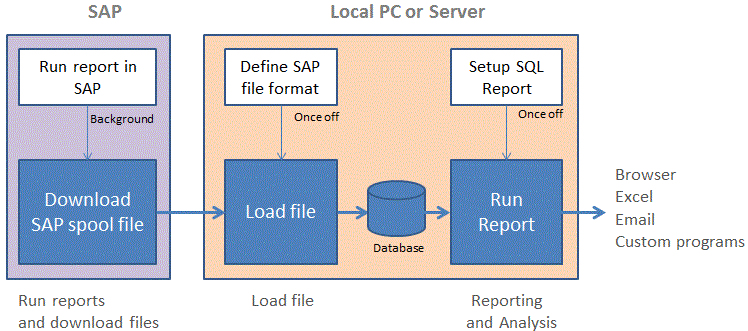
In order to get a consistent file format - all SAP reports must be run in BACKGROUND mode. The reason is that (1) a spoolfile is created that can be downloaded and (2) the spoolfile has a consistent format. In this case with a | separator.
For our example - we will download Customer masters and produce a simple report showing number of customers per country. Customer basic data is stored in Table KNA1 so we will download it from there using SE16N.
[Getting data from SAP
Before we can use Spoolkit - lets get a sample ‘spool’ file from SAP. SAP create a spool file when you run any report in background mode. You can use SE16, SE16N, SQVI or any other SAP report in background mode and then download the file via SM37 or SP01.
In this example here I will be using SE16N to download information from Customer Master – General data table.
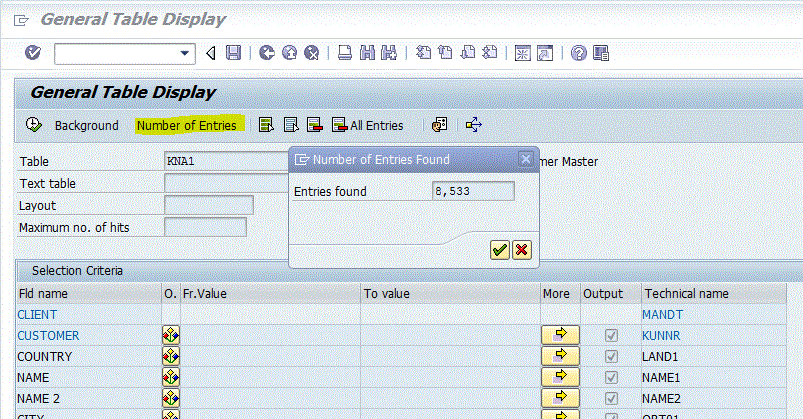
In this case not a lot of records -so file should be small (it was 9MB). It is important that you run the report in background (as a job) and not in foreground mode. Menu: Table Display -> Execute -> Background (or Ctrl-F8).
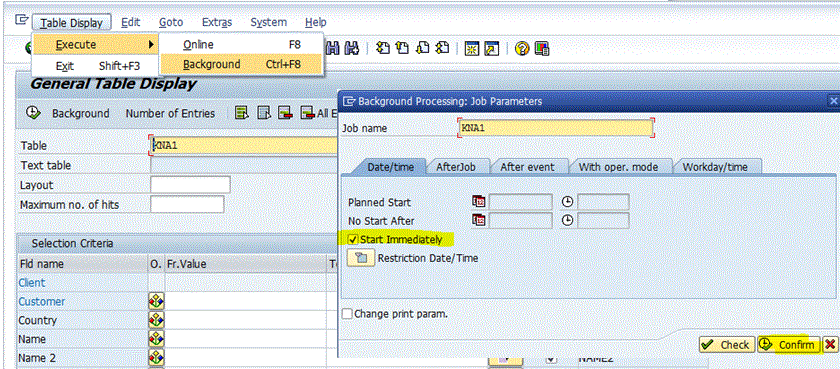
You can track progress of your background job via SM37 and when done download via transaction SM37 (or via SP01 if you want to download multiple files at once).
Download file to your PC
Use SAP transactions SM37 to view status of background job and SP01 to select file created.
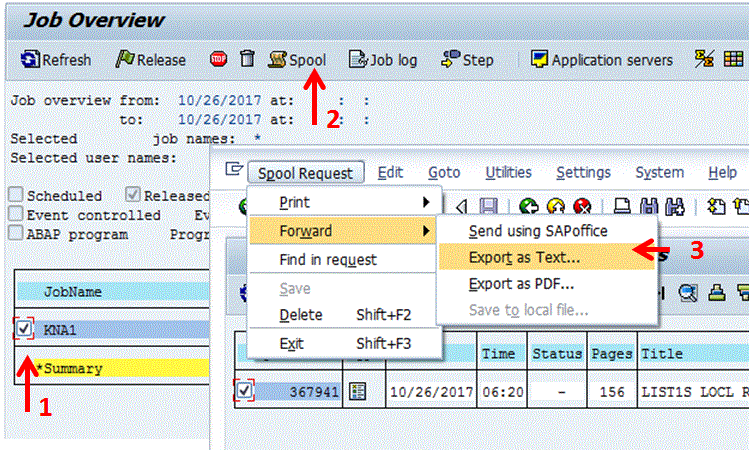
Step 1 - When job is Finished
Step 2 - Select the job you and click on Spool. You can also access this via transaction SP01
Step 3 - To start the download to your PC goto Menu: Spool Request => Forward => Export as Text
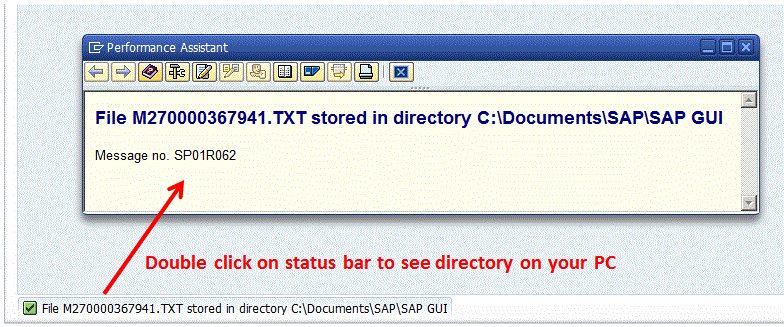
When you see this message (on bottom / left of screen) the process is complete and the file is on your PC. The filename is the made up of first 3 characters of your SAP system name + spool number followed by .TXT
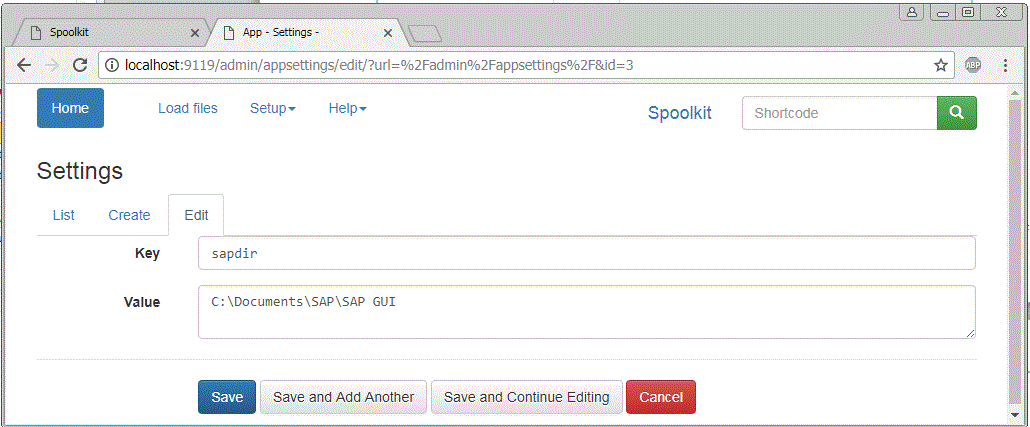
Double click on Status bar to see the full directory where the file was saved on your PC. Copy path to your clipboard as you will be using it later again. For me it was: C:\Documents\SAP\SAP GUI. If required, this directory can be changed in SAP.
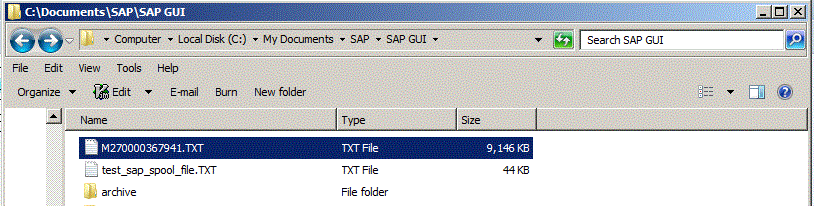
Use Windows Explorer to confirm that file it is on your PC. Also make note of the directory as we will need this later on.
Load data in database with Spoolkit
With Spoolkit running (else run the EXE file) go to Load file http://localhost:9119/loadfiles. Select the folder to use - this is where the downloaded files will be available to load.
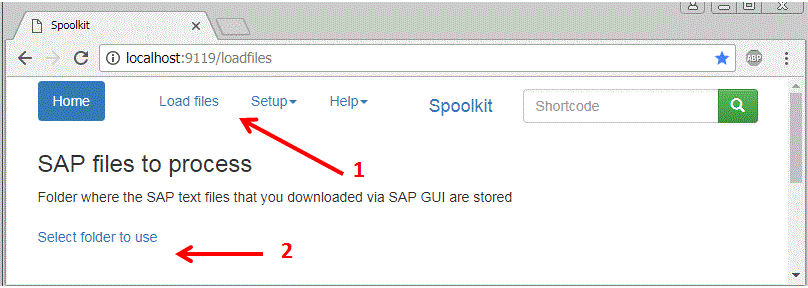
This is the directory where the TXT files will be picked up from. In Setup screen, the key is the sapdir and Value is the directory. Copy / Paste the directory from your file explorer. The directy can be changed at any time via menu: Setup, General Settings.
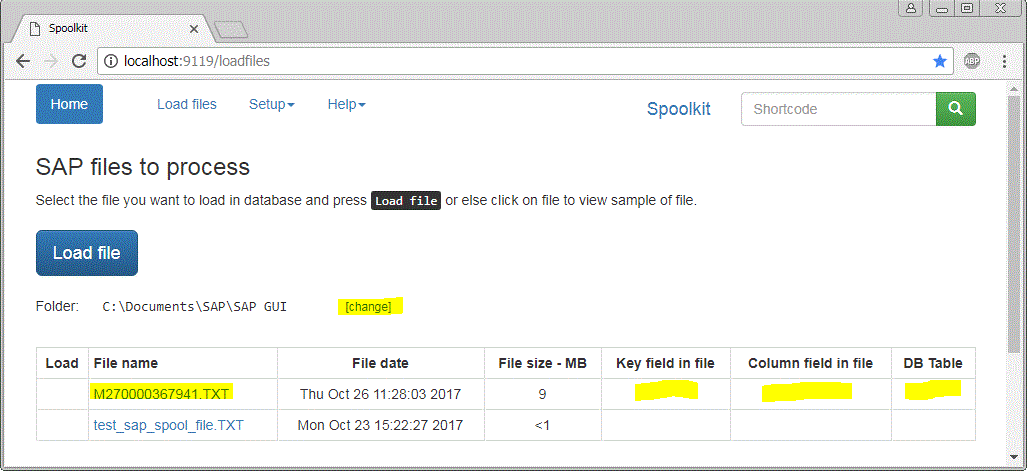
Now that we have specified the directory - click again on “Load File”. You should see your file listed.
In order for Spoolkit to load the data you need to define three things in the setup – which is only done once for every type of file:
(1) The “keyword” to use to identify file type.
(2) Where to get the field names from in the file (“header” field)
(3) In which databse table will the data be loaded
The KEYWORD is simply a unique word that exists in the TXT file that can be used to identify what type of information will be loaded. It is normally the table name (if data originates from SE16N) or the report name if file originated from SQVI or any other SAP report. The more unique the keyword the better.
HEADER FIELD in file is used to pick up the row in the file that will be used to create the field nmaes in the database.
TABLE name is the table where the data will be stored in. You can use any database table name. I typically use the same name as in SAP but start it with “_”. That way I can transform the raw data in the database before storing it in its final table.
In order to identify the keyword and header - you need to have a look at the first few lines in the TXT file. You can do that directly from Spoolkit by clicking on the filename. It will display the first 100 lines on the screen for you so that you can identify suitable “keyword” and “header” fields.
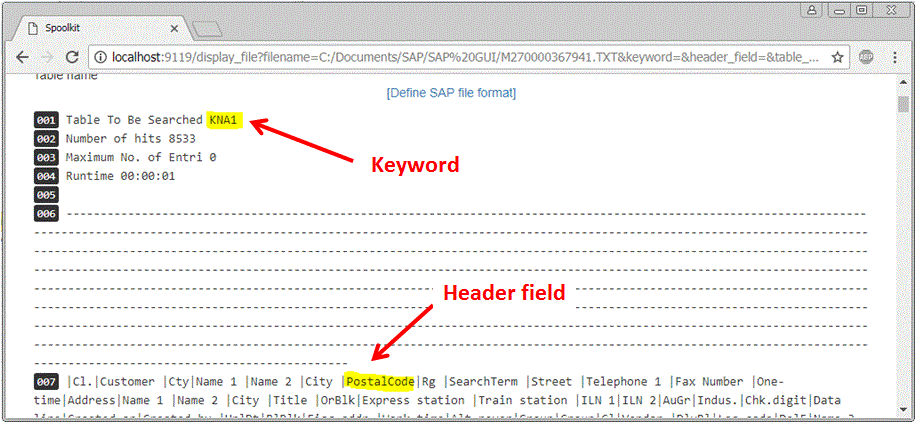
The black numbers on the left are the line number (for info only). In my case I am going to use the text “KNA1” in line 1 as the “keyword” to uniquely identify what type of info this is and the text “postalcode” in line 7 to identify the row that contains the field names. And I want the data to be stored in my database in table r_kna1 (you can pick any suitable database table name)
What the program will do when it loads the file in the database:
- It will scan through the text file and try to find first the “Keyword” and then the “Header” field.
- It will then derive the table name and create a table for us in the database
- It will then load rest of the data in database
Searching for the keyword and header fields in the file is not case sensitive.
When you have identified which “keyword” and “header field” to use – click on Define SAP file format to add the relevant info. http://localhost:9119/admin/filesetup/ Then add a new entry [Create]
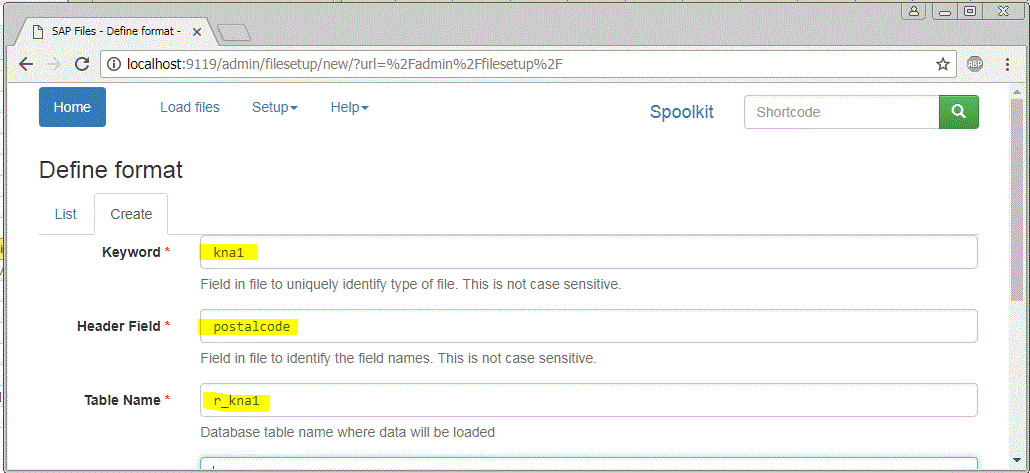
Save
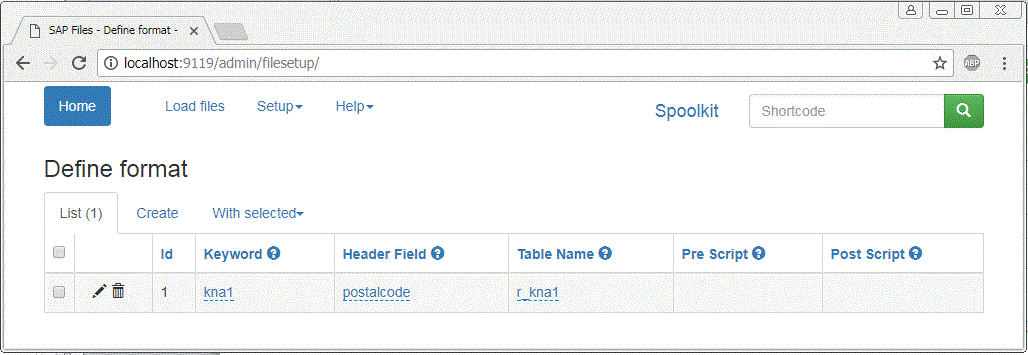
We have now done the required setup for Spoolkit to load the file. In this example – any new file file what has a keyword “kna1” and have a header field with “postalcode” will be loaded into table kna1
Click on “Load Files” again to see if the keyword and Header field were identified in the file. http://localhost:9119/loadfiles
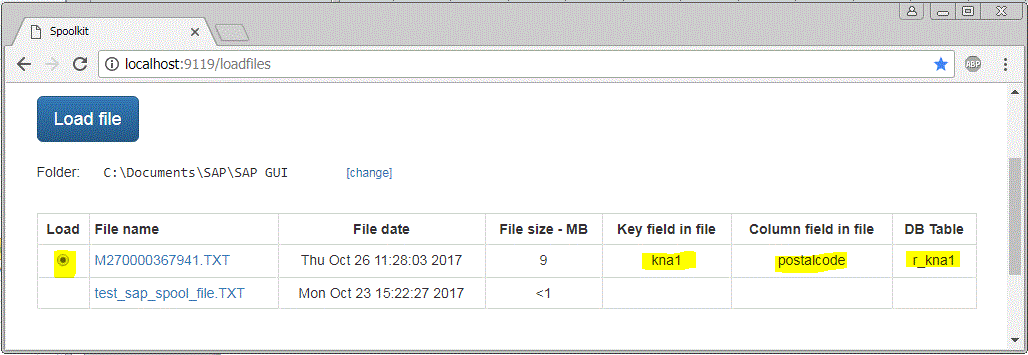
Program has picked up the required fields and which table will be used. You can now select the file with radio button and press “Load file”. If you get the green message, the data was loaded correctly in your database. The SQLite data file will be in the same directory as where your spoolkit.EXE file is and is named spoolkit.db.
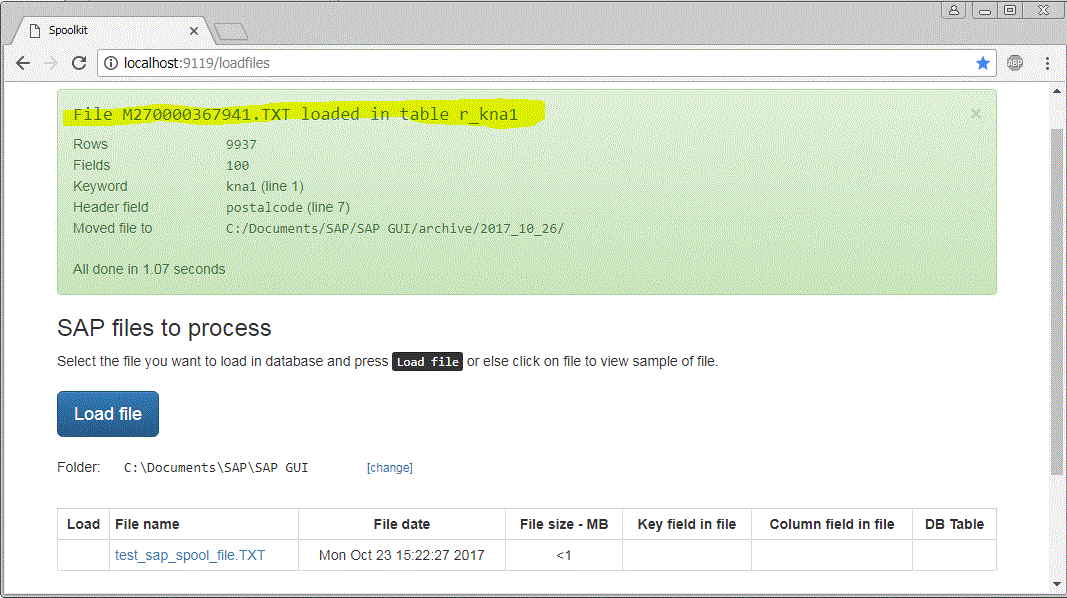
Note that after loading the data successfully in the database, Spoolkit will move the TXT file to a date stamped archive folder. If you need to re-load it again at a later stage, simply move it back and re-do the process.
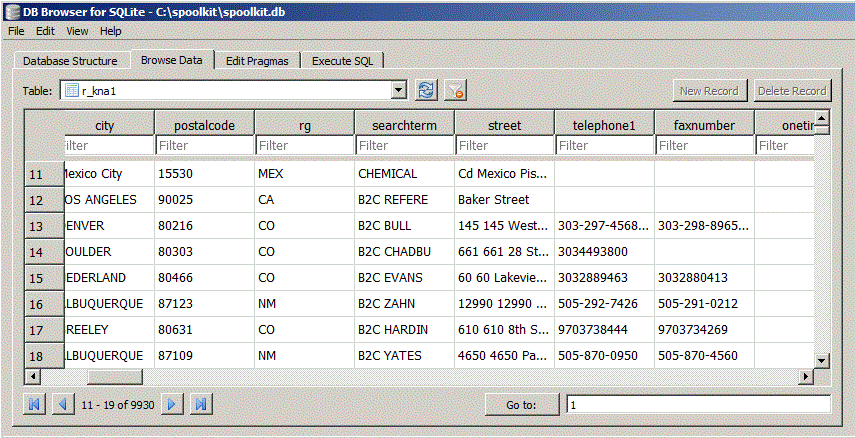
View the data in SQLite database
We now want to produce a report in Spoolkit. Before we do - you want to look at the data in the database - in our case SQLite. Easiest way to view the data and get going with SQL is to use one of the free SQLite browser apps. You can also use these 3rd party tools to test your SQL statements before creating a report in Spookit. I was using “DB Browser” for SQLite - http://sqLitebrowser.org/. Here is the data I loaded as displayed with DB Browser for SQLite.
TIP: SQLIte is not a client-server database and care should be taken not to lock the database. If you use another program with your SQLite datafile, open the database in Read only mode if possible.
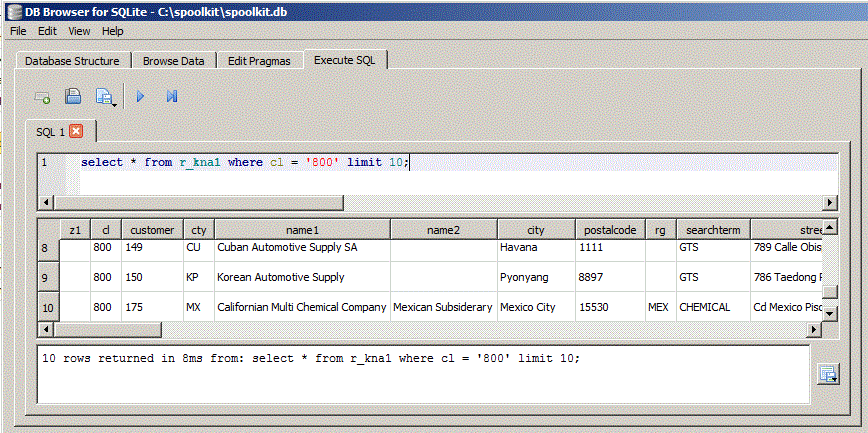
Lets try running a few SQL statement using the - DB Browser for SQLite
select * from r_kna1 where cl = '800' limit 10;
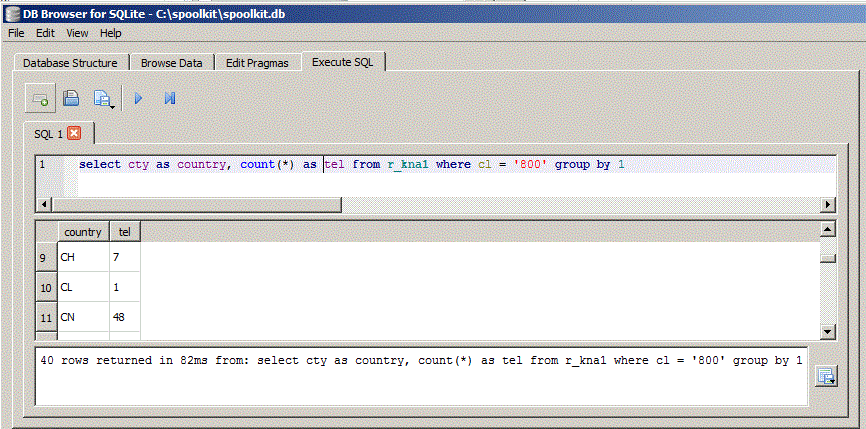
Lets get number of customers per country. Similar to what you would do with a pivot table in Excel.
select cty as country, count(*) as tel from r_kna1 where cl = '800' group by 1;
Build SQL report in Spoolkit
We now want to deploy the above two SQL statement as a Spoolkit report. In Spoolkit, create a new report under Setup, Build reports menu. http://localhost:9119/admin/setup/
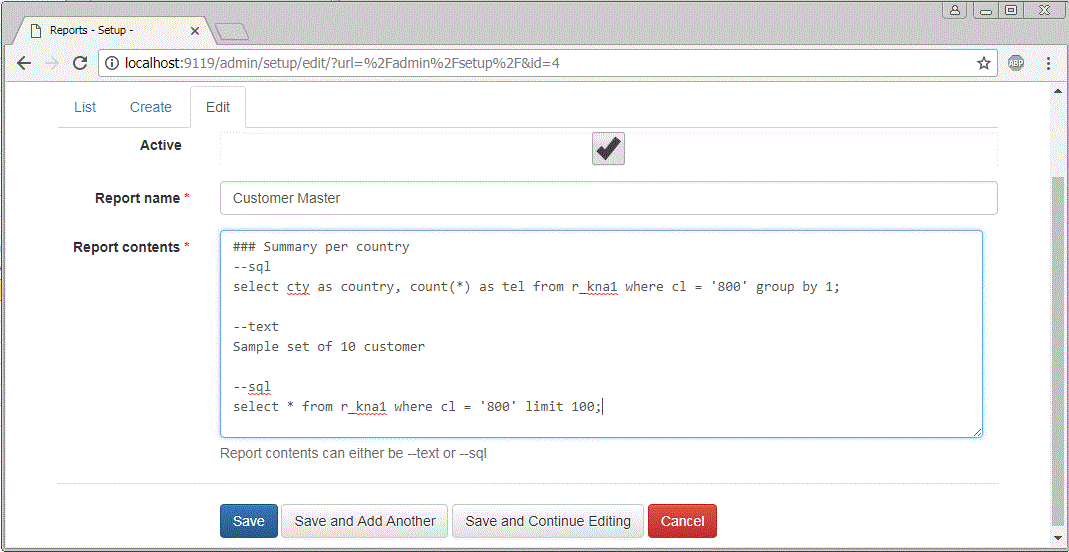
select cty as country, count(*) as tel from r_kna1 where cl = '800' group by 1;
--text
Sample set of 10 customer
--sql
select * from r_kna1 where cl = '800' limit 100;
Quite a lot happening here - some clarification. In a Spoolkit reports – you can have text or result of one or more SQL statements. Text can be formated as per Markdown format. In order for the program to identify if it is SQL or TEXT you need to start a new section with --text or --sql when building a report.
Key points when creating a report:
- Spoolkit reports can consists of either Text or results of one or more SQL statements.
- Add a line with
--sqlindicates that following lines will be a SQL statement - Add a line with
--textindicates that following lines will be text or comments - The default type is
--textand if there are at least 5 empty lines, it will also revert back to Text
A sample report was (report 1) was included in the deployment. It consists of text and more than one SQL statement.
Run Report
A list of reports are on home page - click and run to see result
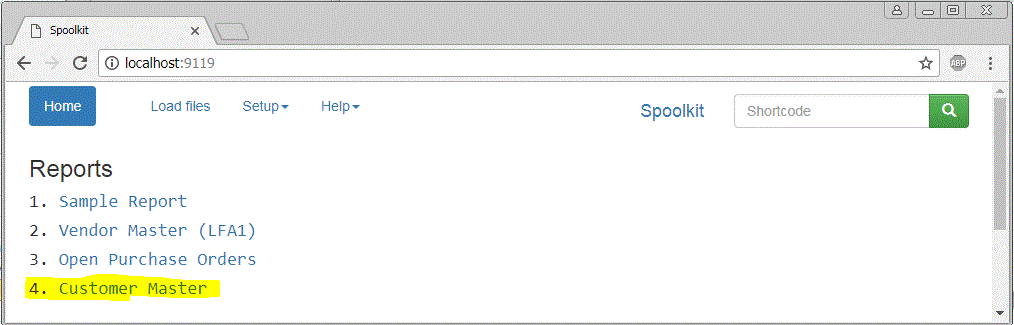
Sample report
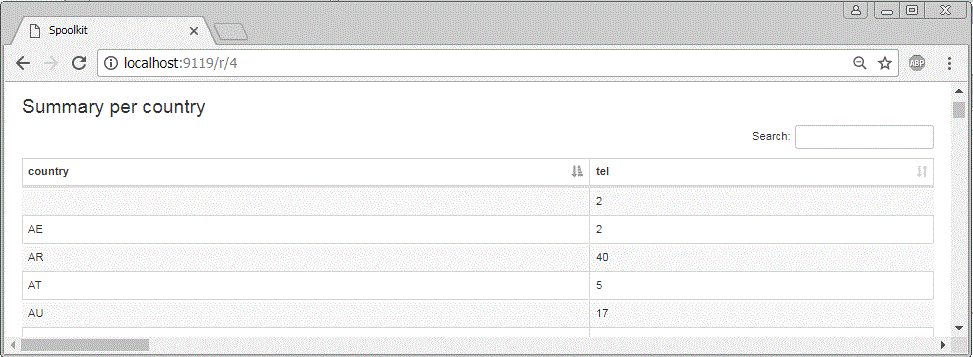
With end to end process working. You should now be able to reprocess a new spoolfile file very quickly and get the updated automated report in seconds. For table data best to use SQVI (rather than SE16N) and save a specific variant. That way you know the table fields will always be consistent.
Downloads and Support
Save file in a separate folder on your PC and execute EXE to start using immediately.
Here is a sample text file in same format as produced by SAP. You can use this to follow along if you don’t have access to SAP. ides_customer_masters.TXT
Support
Spoolkit is currently in early Alpha mode. It is therefore full of bugs and might not even run on your PC. Updates are available on regular bases â please check back or email me directly if you have any comments. To upgrade, simply download the new EXE file and save it in your working folder.
If you find this post or program or have any comments or question please make contact with me. My contact details are on the Spoolkit website. You can report any issues or proposed enhancements here: https://bitbucket.org/matimba/spoolkit/issues/new
Thank you for reading this post.